Abstract
Social relation reasoning aims to identify relation categories such as friends, spouses, and colleagues from images. While current methods adopt the paradigm of training a dedicated network end-to-end using labeled image data, they are limited in terms of generalizability and interpretability. To address these issues, we first present a simple yet well-crafted framework named SocialGPT, which combines the perception capability of Vision Foundation Models (VFMs) and the reasoning capability of Large Language Models (LLMs) within a modular framework, providing a strong baseline for social relation recognition. Specifically, we instruct VFMs to translate image content into a textual social story, and then utilize LLMs for text-based reasoning. SocialGPT introduces systematic design principles to adapt VFMs and LLMs separately and bridge their gaps. Without additional model training, it achieves competitive zero-shot results on two databases while offering interpretable answers, as LLMs can generate language-based explanations for the decisions. The manual prompt design process for LLMs at the reasoning phase is tedious and an automated prompt optimization method is desired. As we essentially convert a visual classification task into a generative task of LLMs, automatic prompt optimization encounters a unique long prompt optimization issue. To address this issue, we further propose the Greedy Segment Prompt Optimization (GSPO), which performs a greedy search by utilizing gradient information at the segment level. Experimental results show that GSPO significantly improves performance, and our method also generalizes to different image styles.
Figures

Figure 1: (a) End-to-end learning-based framework for social relation reasoning. A dedicated neural network is trained end-to-end with full training data. (b) We propose a modular framework with foundation models for social relation reasoning. Our proposed SocialGPT first employs VFMs to extract visual information into textual format, and then perform text-based reasoning with LLMs, using either our manually designed SocialPrompt or optimized prompts.
Approach
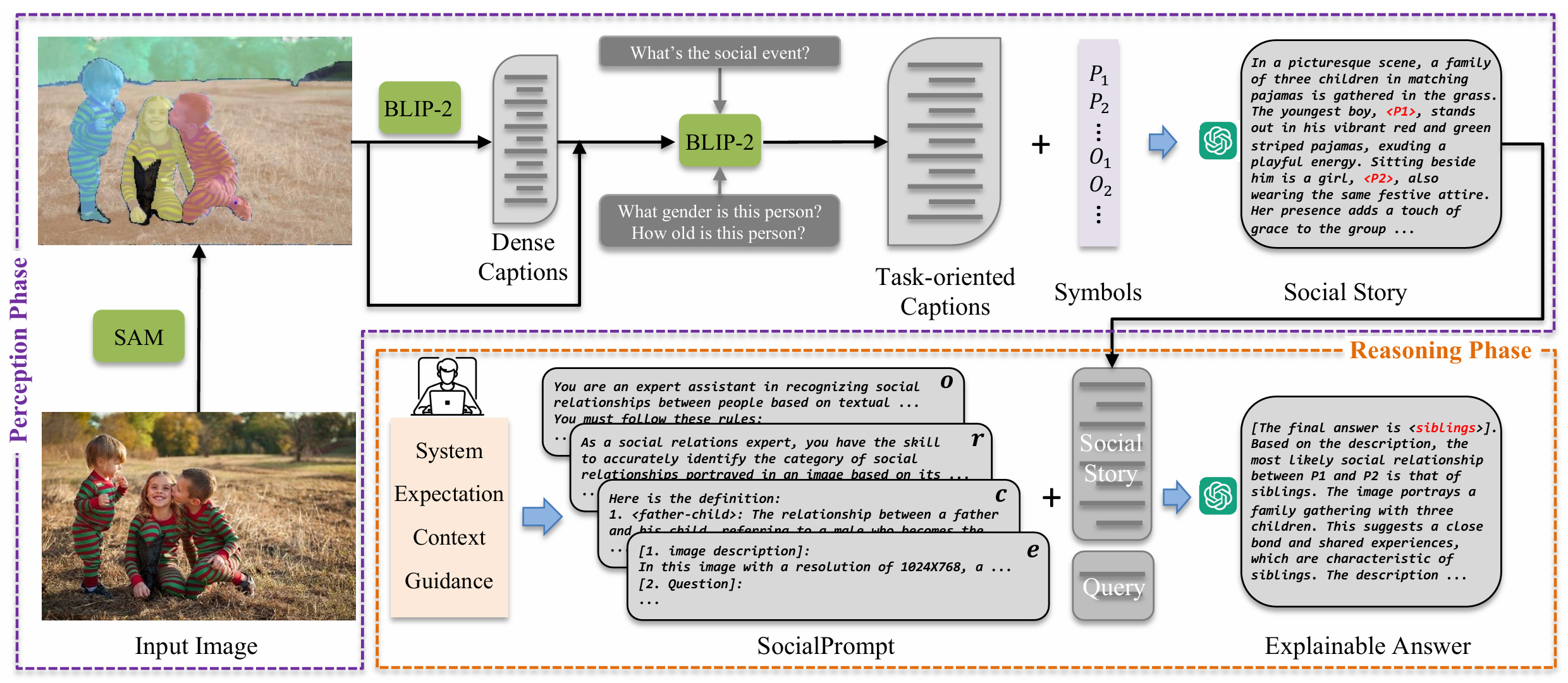
Figure 2: The framework of SocialGPT, which follows the "perception with VFMs, reasoning with LLMs" paradigm. SocialGPT converts an image into a social story in the perception phase, and then employs LLMs to generate explainable answers in the reasoning phase with SocialPrompt.
Results
- Without additional model training, SocialGPT achieves competitive zero-shot results on two databases while offering interpretable answers, as LLMs can generate language-based explanations for the decisions.
- Experimental results show that GSPO significantly improves performance, and our method also generalizes to different image styles.

Figure 3: An example of social story generation.

Figure 4: Visualization results of interpretability. We show the SocialGPT perception and reasoning process. We see that our model predicts correct social relationships with plausible explanations.

Figure 5: Results when applying SocialGPT to sketch and cartoon images. The images are generated by GPT-4V. Our method generalizes well on these novel image styles.
Tables
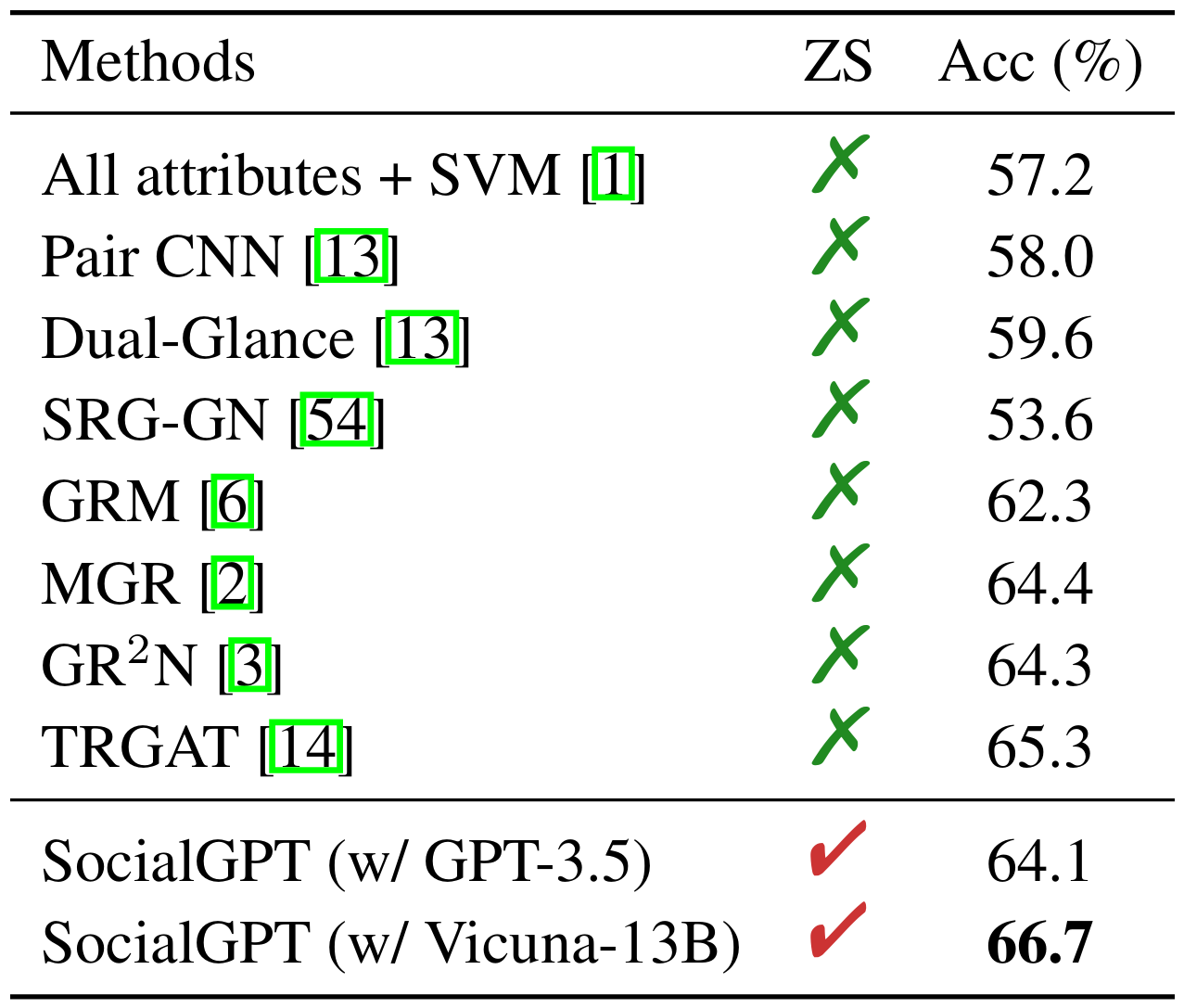
Table 1: The comparison results on the PIPA dataset. ZS stands for Zero-Shot.
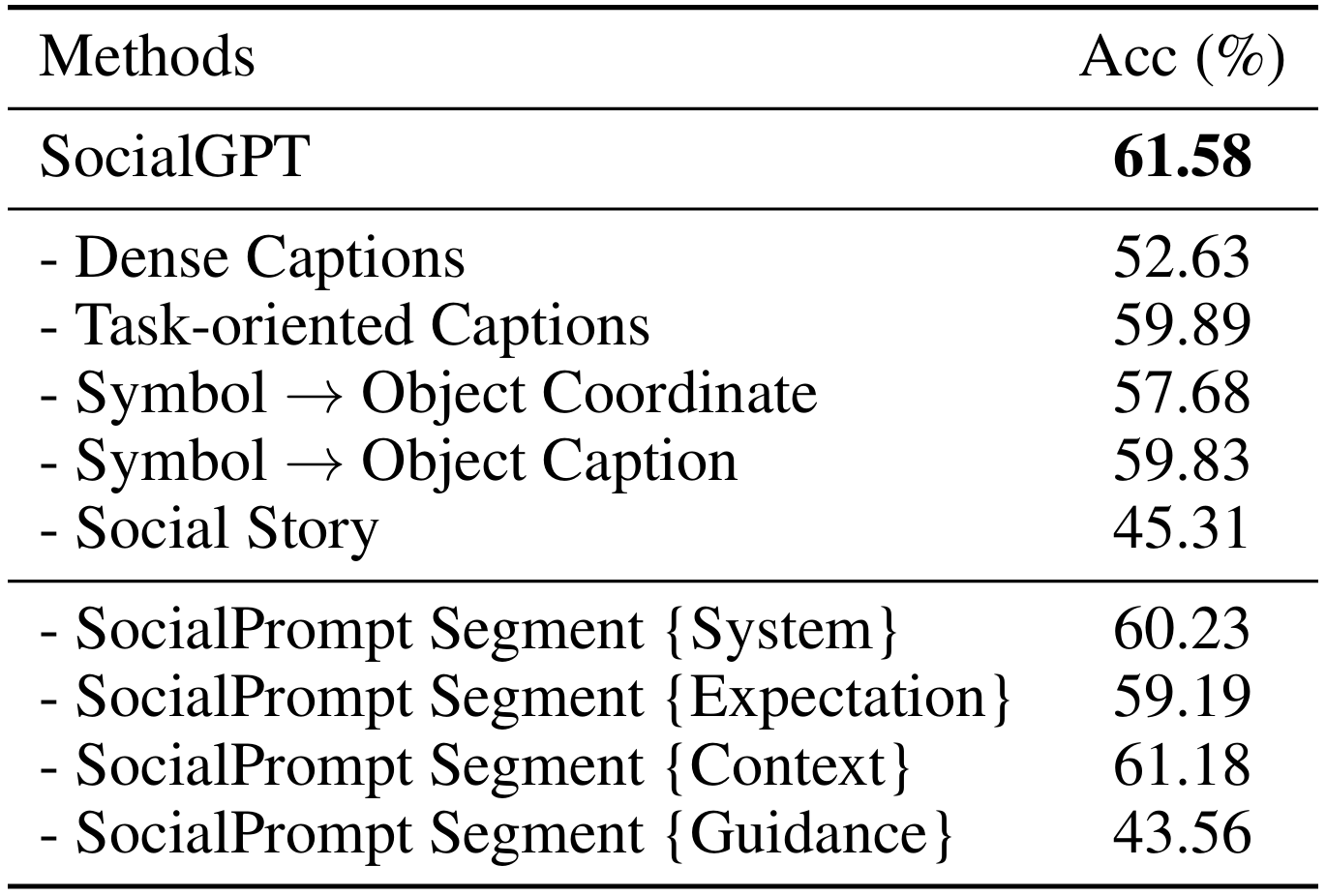
Table 2: Ablations on components of SocialGPT with Vicuna-7B. The results are obtained on the PIPA dataset with a zero-shot setting.
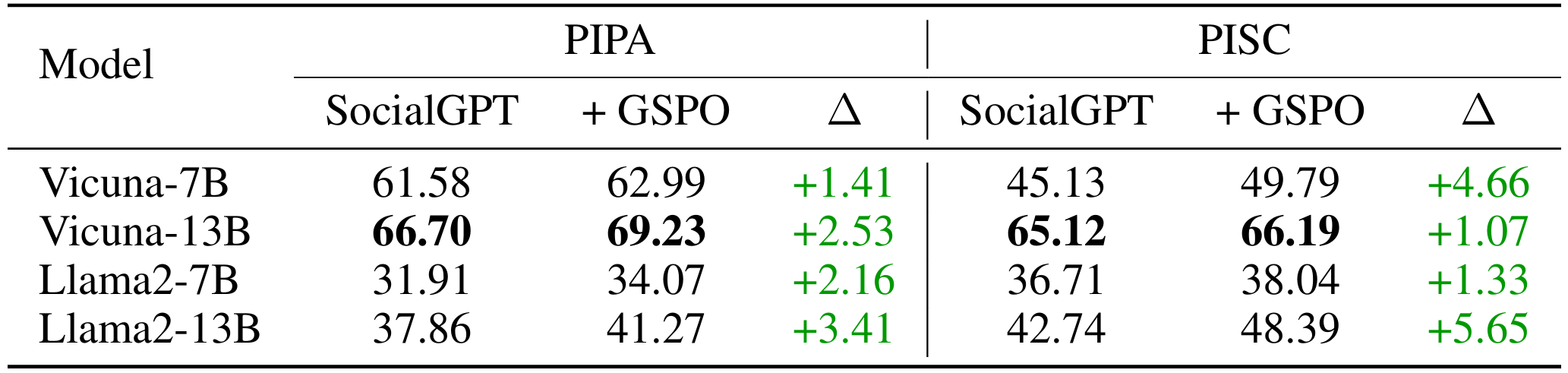
Table 3: Prompt tuning results (accuracy in %) with GSPO.